株の売買は人間が行うと、
運勝負になってしまうのではないか、
ファンダメンタルズとテクニカルどっちを信じればいいんだと、
とにかく悩むことが多いですよね。
今回は、Pythonで株価のデータ分析と予測をしてみようと思います。
テクニカル分析を機械にやってもらえば、人間より高速に完璧にやってくれるのではないかという淡い期待を持ってやっています。
データを集める。
まずはデータを集める必要があります。
今回はアップル(AAPL)の過去の株価の記録を使います。
まずは後から使うライブラリをインポートします。
# 日付と時間を操作するためのライブラリ
import datetime
# データの可視化のためのライブラリ
import matplotlib.pyplot as plt
# 数値演算やデータ操作のためのライブラリ
import numpy as np
# 金融データを取得するためのライブラリ
import pandas_datareader.data
# 機械学習モデルを構築するためのライブラリ
import sklearn.linear_model
import sklearn.model_selection
# 金融データを取得するためのライブラリ
import yfinance次にpandas-datareaderを使って、AAPLの株価の情報をゲットします。
どうやらYahooのAPIの仕様の変更があったみたいで、本に書いてあるコードではうまくいきませんでした。ネットで調べたらうまくいく方法が見つかりました。
# yahooの仕様の変化によってyfinanceを入れないといけないみたい
yfinance.pdr_override()
# 株価をゲットする期間を指定する
start = datetime.date(2020, 1, 1)
end = datetime.date(2023, 10, 1)
# 古い本では株価を取得するAPIとして"yahoo"を指定していたが、要らなくなった
df_aapl = pandas_datareader.data.DataReader('AAPL', start, end)
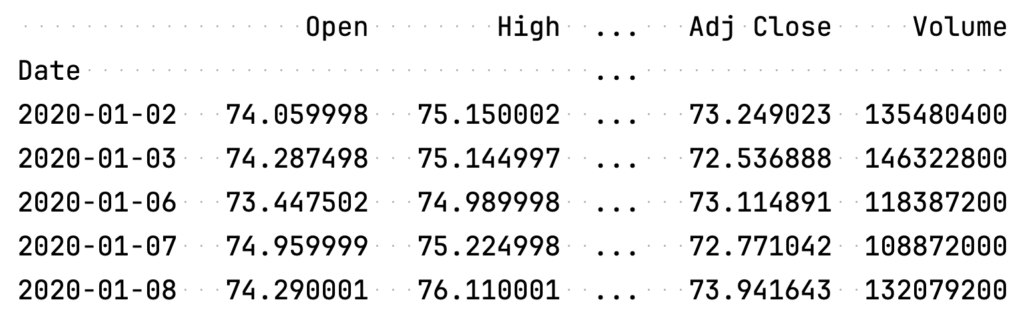
print(df_aapl)実行結果はこんな感じです。
特徴量と予測変数を作成
特徴量は、機械学習の際に機械に勉強させるための材料みたいなものです。
今回は株価のテクニカル分析でよく使われる移動平均線を使います。
予測変数は、言葉通り予測したい値のことです。今回は未来の株価を予測をしたいので30日後の終値ということにします。
コードは、rollingとmeanを使えば簡単です。
プロットをするとうまくいっているのかがわかります。色は適当です。
# 15, 30, 60日の平均をデータフレームに追加
df_aapl['SMA_15'] = df_aapl['Close'].rolling(window=15).mean()
df_aapl['SMA_30'] = df_aapl['Close'].rolling(window=30).mean()
df_aapl['SMA_60'] = df_aapl['Close'].rolling(window=60).mean()
# 30日後の終値もデータフレームに入れる
df_aapl['Close_30'] = df_aapl['Close'].shift(-30)
# データフレームの列と色を指定しプロットする
df_aapl['Close'].plot(figsize=(15, 6), color='red')
df_aapl['SMA_15'].plot(figsize=(15, 6), color='green')
df_aapl['SMA_30'].plot(figsize=(15, 6), color='blue')
df_aapl['SMA_60'].plot(figsize=(15, 6), color='pink')
# グラフを表示します。
plt.show()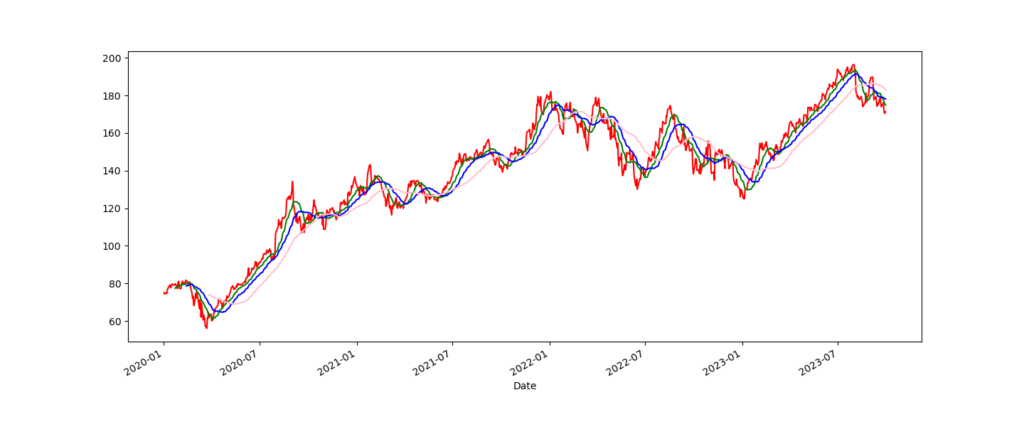
機械に株価の予測をしてもらう
まずはデータの中身の確認します。
30日後のデータの入っている”Close_30″を見てみると、NaN (Not a Number)が入っています。
これは最後の方の日付は30日後のデータがないからです。
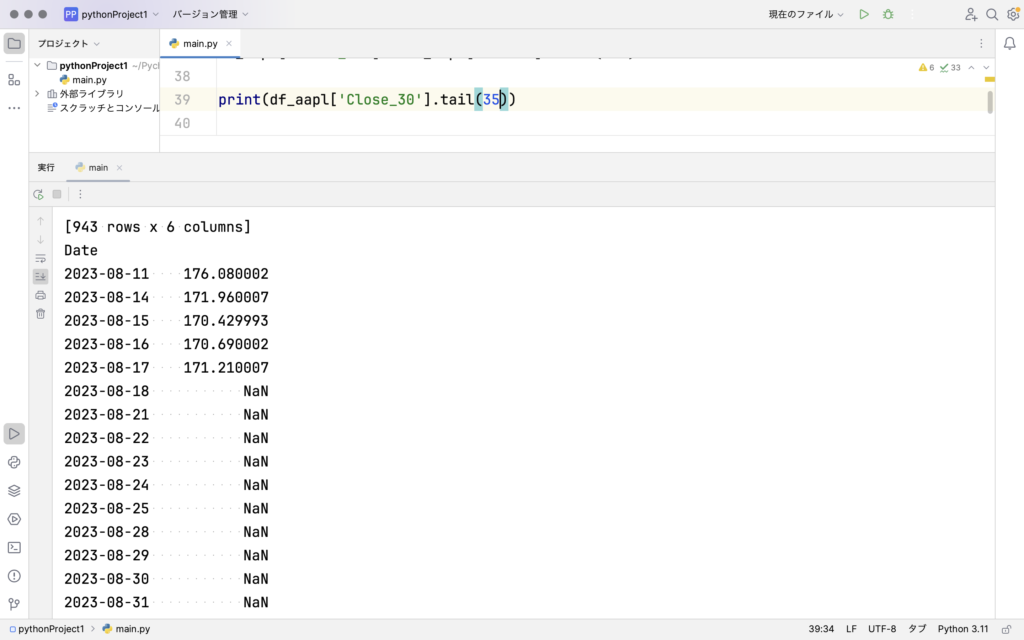
同様に移動平均を求めたときにも60日分の平均を出したので、60日目以降からしか数値が入っていません。
これを確認したので、機械にデータを渡すときに取り除くことを忘れないように気を付けます。
ようやく機械学習です。
線形回帰アルゴリズムを使います。
アルゴリズムに学習させるデータを変数Xに、予測したいデータの答えをyに与えます。
scale()は平均から大きく外れたデータを自動的に外してくれます。
訓練用データとテスト用データに分けるのは、ホールドアウト法というみたいです。
# df_aaplから予測したいデータを抜いたものをXに代入
X = np.array(df_aapl.drop(['Close_30'], axis='columns'))
# 平均値から大きく離れているものを除去
X = sklearn.preprocessing.scale(X)
# 正解のデータをyに代入
y = np.array(df_aapl['Close_30'])
# データの最初の60行と最後の30行はNaNが入っているので除く
y = y[60:-30]
X = X[60:-30]
# 訓練用データとテスト用データに分ける
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2)
# 線形回帰アルゴリズムのオブジェクトを作成し学習、線形回帰を略してlr
lr = sklearn.linear_model.LinearRegression()
lr.fit(X_train, y_train)
# 正確さの計算
accuracy = lr.score(X_test, y_test)
print(accuracy)最後の正確さの結果は、0.7584997265474441でした。まあまあですかね。
予測をグラフにして視覚化
正確さを数値で渡されてもよくわからないですよね。
実際のグラフとどれくらい違いがあるのかを視覚的に見てみます。
# 線形回帰モデル (lr) を使用して、Xの最後の30要素に対する予測データを取得
predict_data = lr.predict(X[-30:])
# DataFrame(ここではdf_aapl)に新しい列 'predict' を追加し、初期値をNaN(非数値)に設定します。
df_aapl['predict'] = np.nan
# データフレームの最後の行の日付を取得します。
last_date = df_aapl.iloc[-1].name
# 86400は1日の秒数を表す
one_day = 86400
# 次の日の日付を計算します。最後の日付に1日分の秒数を加えます。
next_day = last_date.timestamp() + one_day
# 予測データをデータフレームに追加していく。
for data in predict_data:
# 次の日の日付をタイムスタンプから変換して取得します。
next_date = datetime.datetime.fromtimestamp(next_day)
# 'Predict' 列に予測データを追加
df_aapl.loc[next_date, 'Predict'] = data
# 次の日の日付を更新します。
next_day += one_day
df_aapl['Close'].plot(figsize=(6, 6), color='red')
df_aapl['Predict'].plot(figsize=(6, 6), color='pink')
plt.show()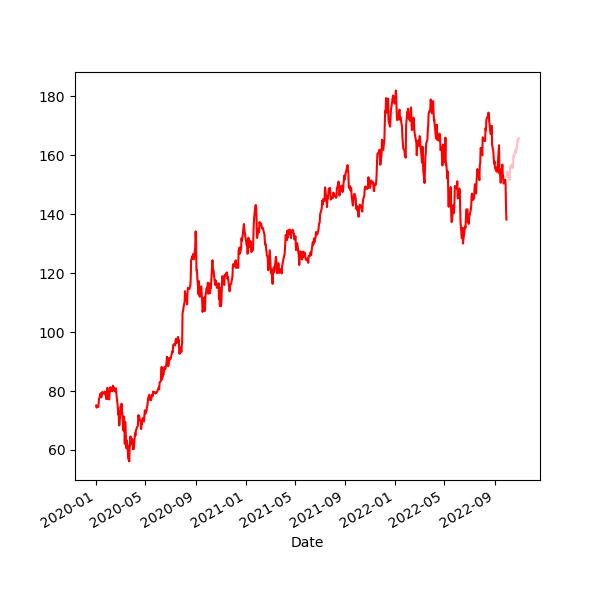
まとめ
今回は、Pythonを使って株価の予測の方法を順を追って説明しました。
まだまだ特徴量の選定や、アルゴリズムの変更などと試してみたいことは山ほどです。
いつか機械に学習させて勝手に売買してもらい億万長者になりたいですね笑
ありがとうございました。


コメント