
ファンダメンタルズとテクニカルどっちを信じればいいんだと、とにかく悩むことが多いですよね。
今回は、Pythonでビットコインのデータを利用し、データフレームを整理確認し、基本的な特徴量を作ろうと思います。Kaggleなどのデータ分析コンペでも最初に行う操作ですのでぜひ覚えましょう。
参考にさせてもらったページは以下のサイトです。
- https://github.com/richmanbtc/mlbot_tutorial
- https://github.com/richmanbtc/crypto_data_fetcher
(テクニカル分析を機械にやってもらえば、人間より高速に完璧にやってくれるのではないかという淡い期待を持ってやっています。)
今回はJupyter notebookを使っています。
データの読み込み
まずはビットコインの過去の価格データを読み込みます。今回はcsvファイルを用意しておいたので、読み込みます。csvファイルを読み込む時にはpandasの「read_csv」を使います。
import pandas as pd
df = pd.read_csv("df_ohlcv_1h.csv")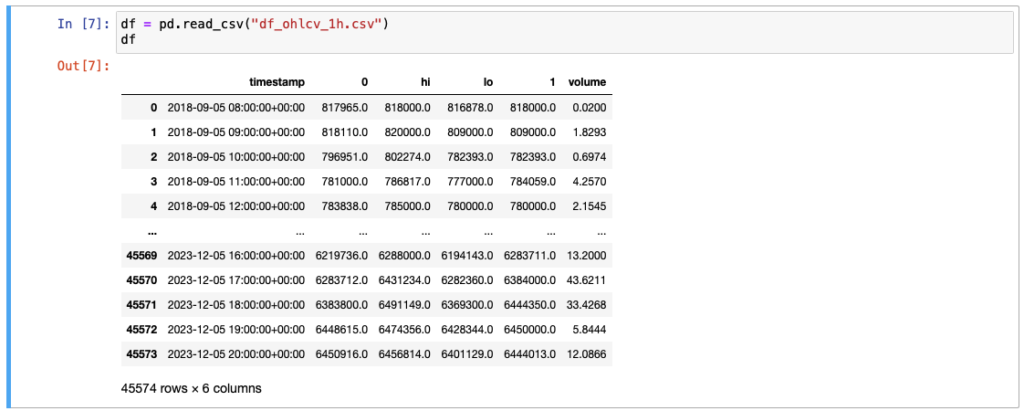
インデックスとカラムの命名
読み込んだデータを見るとインデックスが整数に、カラム名が「1」や「0」になっており、後々見にくくなってくるので、名前を変更しておきます。カラム名は、始値、高値、安値、終値、取引量を英語にしたときの頭文字にしておきます。
# "timestamp"の列をインデックスに設定
df = df.set_index("timestamp")
# カラム名を一括で変更
df.columns = ["op","hi","lo","cl","volume"]
df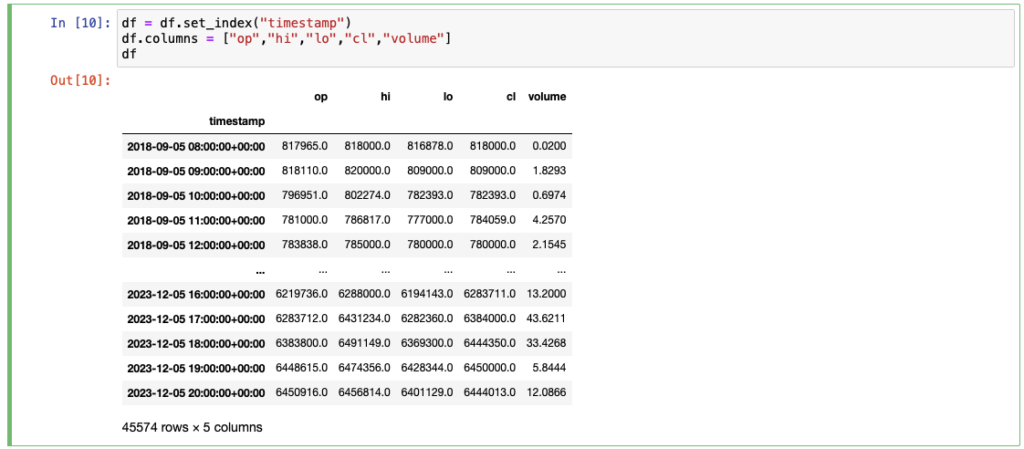
特徴量作成
特徴量を作っていきます。今回はとりあえずいっぱい作っておきます。後で、無い方が良い特徴量を消せばいいので考えられる特徴量を作っておきます。
特徴量を作るときに気をつけるべきポイントは以下の3点です。
- 未来の情報を含めない
- 古すぎる情報も含めない
- 本番環境で取得できない情報を含めない
特徴量は以下のライブラリが便利みたいです。
- TA-Lib
- https://github.com/bukosabino/ta
また価格を見ると2018年9月では約80万円で、2023年12月では約640万円です。機械学習で決定技を使う時には、精度がかなり悪くなってしまうので正規化しておきます。
import talib
def calc_features(df):
open = df['op']
high = df['hi']
low = df['lo']
close = df['cl']
volume = df['volume']
orig_columns = df.columns
hilo = (df['hi'] + df['lo']) / 2
# Bollinger Bands features
df['BBANDS_upperband'], df['BBANDS_middleband'], df['BBANDS_lowerband'] = talib.BBANDS(close, timeperiod=5, nbdevup=2, nbdevdn=2, matype=0)
df['BBANDS_upperband'] = (df['BBANDS_upperband'] - hilo) / close
df['BBANDS_middleband'] = (df['BBANDS_middleband'] - hilo) / close
df['BBANDS_lowerband'] = (df['BBANDS_lowerband'] - hilo) / close
# Double Exponential Moving Average (DEMA) feature
df['DEMA'] = (talib.DEMA(close, timeperiod=30) - hilo) / close
# Exponential Moving Average (EMA) feature
df['EMA'] = (talib.EMA(close, timeperiod=30) - hilo) / close
# Hilbert Transform - Trendline feature
df['HT_TRENDLINE'] = (talib.HT_TRENDLINE(close) - hilo) / close
# Kaufman Adaptive Moving Average (KAMA) feature
df['KAMA'] = (talib.KAMA(close, timeperiod=30) - hilo) / close
# Moving Average (MA) feature
df['MA'] = (talib.MA(close, timeperiod=30, matype=0) - hilo) / close
# Midpoint over period feature
df['MIDPOINT'] = (talib.MIDPOINT(close, timeperiod=14) - hilo) / close
# Simple Moving Average (SMA) feature
df['SMA'] = (talib.SMA(close, timeperiod=30) - hilo) / close
# Triple Exponential Moving Average (T3) feature
df['T3'] = (talib.T3(close, timeperiod=5, vfactor=0) - hilo) / close
# Triple Exponential Moving Average (TEMA) feature
df['TEMA'] = (talib.TEMA(close, timeperiod=30) - hilo) / close
# Triangular Moving Average (TRIMA) feature
df['TRIMA'] = (talib.TRIMA(close, timeperiod=30) - hilo) / close
# Weighted Moving Average (WMA) feature
df['WMA'] = (talib.WMA(close, timeperiod=30) - hilo) / close
# Linear Regression feature
df['LINEARREG'] = (talib.LINEARREG(close, timeperiod=14) - close) / close
# Linear Regression Intercept feature
df['LINEARREG_INTERCEPT'] = (talib.LINEARREG_INTERCEPT(close, timeperiod=14) - close) / close
# Volume-based features
df['AD'] = talib.AD(high, low, close, volume) / close
df['ADOSC'] = talib.ADOSC(high, low, close, volume, fastperiod=3, slowperiod=10) / close
df['APO'] = talib.APO(close, fastperiod=12, slowperiod=26, matype=0) / close
df['HT_PHASOR_inphase'], df['HT_PHASOR_quadrature'] = talib.HT_PHASOR(close)
df['HT_PHASOR_inphase'] /= close
df['HT_PHASOR_quadrature'] /= close
df['LINEARREG_SLOPE'] = talib.LINEARREG_SLOPE(close, timeperiod=14) / close
df['MACD_macd'], df['MACD_macdsignal'], df['MACD_macdhist'] = talib.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9)
df['MACD_macd'] /= close
df['MACD_macdsignal'] /= close
df['MACD_macdhist'] /= close
df['MINUS_DM'] = talib.MINUS_DM(high, low, timeperiod=14) / close
df['MOM'] = talib.MOM(close, timeperiod=10) / close
df['OBV'] = talib.OBV(close, volume) / close
df['PLUS_DM'] = talib.PLUS_DM(high, low, timeperiod=14) / close
df['STDDEV'] = talib.STDDEV(close, timeperiod=5, nbdev=1) / close
df['TRANGE'] = talib.TRANGE(high, low, close) / close
# Trend-based features
df['ADX'] = talib.ADX(high, low, close, timeperiod=14)
df['ADXR'] = talib.ADXR(high, low, close, timeperiod=14)
df['AROON_aroondown'], df['AROON_aroonup'] = talib.AROON(high, low, timeperiod=14)
df['AROONOSC'] = talib.AROONOSC(high, low, timeperiod=14)
df['BOP'] = talib.BOP(open, high, low, close)
df['CCI'] = talib.CCI(high, low, close, timeperiod=14)
df['DX'] = talib.DX(high, low, close, timeperiod=14)
# MFI is Money Flow Index
df['MFI'] = talib.MFI(high, low, close, volume, timeperiod=14)
df['MINUS_DI'] = talib.MINUS_DI(high, low, close, timeperiod=14)
df['PLUS_DI'] = talib.PLUS_DI(high, low, close, timeperiod=14)
df['RSI'] = talib.RSI(close, timeperiod=14)
df['STOCH_slowk'], df['STOCH_slowd'] = talib.STOCH(high, low, close, fastk_period=5, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0)
df['STOCHF_fastk'], df['STOCHF_fastd'] = talib.STOCHF(high, low, close, fastk_period=5, fastd_period=3, fastd_matype=0)
df['STOCHRSI_fastk'], df['STOCHRSI_fastd'] = talib.STOCHRSI(close, timeperiod=14, fastk_period=5, fastd_period=3, fastd_matype=0)
df['TRIX'] = talib.TRIX(close, timeperiod=30)
df['ULTOSC'] = talib.ULTOSC(high, low, close, timeperiod1=7, timeperiod2=14, timeperiod3=28)
df['WILLR'] = talib.WILLR(high, low, close, timeperiod=14)
# Average True Range (ATR) feature
df['ATR'] = talib.ATR(high, low, close, timeperiod=14)
# Normalized Average True Range (NATR) feature
df['NATR'] = talib.NATR(high, low, close, timeperiod=14)
# Hilbert Transform - Dominant Cycle Period feature
df['HT_DCPERIOD'] = talib.HT_DCPERIOD(close)
# Hilbert Transform - Dominant Cycle Phase feature
df['HT_DCPHASE'] = talib.HT_DCPHASE(close)
# Hilbert Transform - Sine and Leadsine features
df['HT_SINE_sine'], df['HT_SINE_leadsine'] = talib.HT_SINE(close)
# Hilbert Transform - Trend Mode feature
df['HT_TRENDMODE'] = talib.HT_TRENDMODE(close)
# Beta feature
df['BETA'] = talib.BETA(high, low, timeperiod=5)
# Pearson correlation coefficient feature
df['CORREL'] = talib.CORREL(high, low, timeperiod=30)
# Linear Regression Angle feature
df['LINEARREG_ANGLE'] = talib.LINEARREG_ANGLE(close, timeperiod=14)
# Creating Normalized lag variables
for i in range(5):
df["LAG_" + str(i + 1)] = df["cl"].shift(i) / df["cl"].shift(i + 1)
return df
df = calc_features(df)
df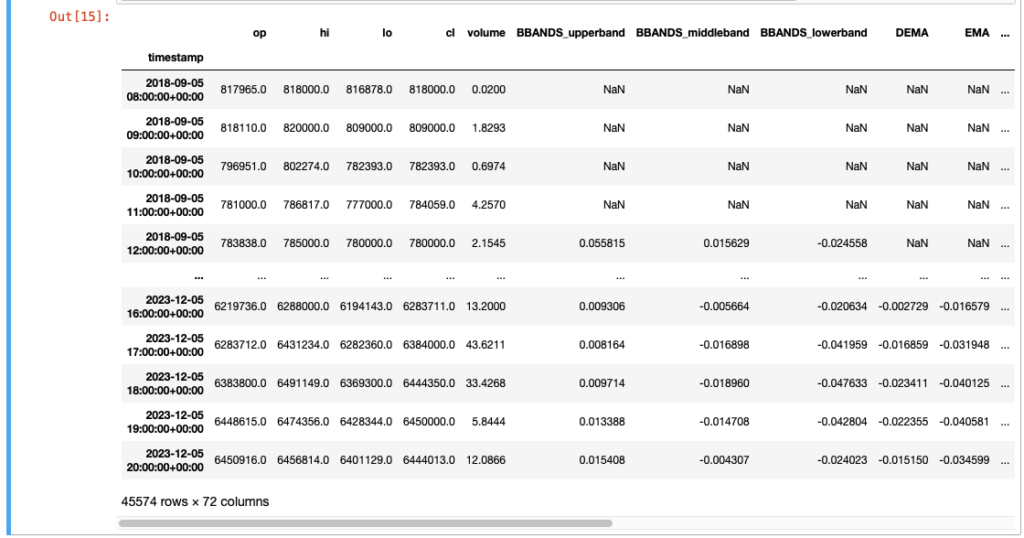
まとめ
今回はカラムとインデックスの整理、特徴量を作成する方法を紹介しました。
ビットコインの価格変動は、ランダムウォークですが、分析することによって未来の価格が分かるかもしれません。それが分かれば、儲けることができるかもしれません。夢かもしれません。
続きも書いていこうと思ってます。

コメント